Published on 10 Apr 2024

Exploring AI Tools for Developers: Insights from PozTechTalks part 2
Magdalena
Employer Branding Specialist
CTO & Co-founder

An honest accounting of where the speed came from, where it didn't, and which parts of the work we'd never hand to a machine.


~5.4× less developer time on the dev portion alone — and the new site has more pages, more animation, full Strapi integration for blog and case studies, and SEO/GEO scaffolding the old one never had.
The repo itself, audited from git log between
2026-04-08
(first commit) and
2026-06-02
(launch-ready):
Calendar span: 56 days (~8 weeks).
Active development days: 25. The other 31 were design, copy, review, QA, and waiting on decisions — all the work the model doesn't do.
Total commits: 181. Every one of them generated by Claude Code, reviewed by Claude Code in a fresh-context pass, signed off by a human.
Lines added / removed: 47,173 inserted, 5,676 deleted, across 857 file-changes.
Codebase shape today:
24,296 LOC across 120 .tsx files, 47 .ts files, and a single .css file (Tailwind v4 — yes, one stylesheet).
Focused coding time: ~78 hours across 53 discrete sessions. (Method: sum the wall-clock intervals between commits within a session; a gap longer than 90 minutes starts a new session. It's not a billing-grade figure, but it's the right shape.)
Average commit: ~26 minutes of attention. Most diffs are small enough to read in under a minute. That's deliberate.
Claude Code — for code generation and for the code review pass.
Figma MCP — the design system, components, frames, variables, and motion prototypes live in Figma and the model reads them directly. No "implement from screenshot" guesswork.
Stack: TanStack Start + Vite 7 + React 19 + Motion 12 + Tailwind v4. Strapi as the CMS. Resend for the contact form.
52,800 changed lines × 70 chars ÷ 4 chars-per-token = 925k output tokens of shipped code.
With read context, retries, and review passes, end-to-end usage was roughly ~10–20 million tokens.
We actually paid for this with a Claude Max plan, but if you're estimating for your own team on pay-as-you-go API rates with prompt caching, the equivalent cost lands roughly $90–$180 depending on your Opus/Sonnet mix — Opus-heavy with effective caching sits near the top of that, a Sonnet-leaning mix near the bottom. Budget $200 and you'll almost certainly come in under it.
420 hours of typing replaced by 78 hours of judgment. The judgment is the part you can't outsource.
If we had to pick the single moment that justified the whole approach, it would be May 20, 2026 — the day we ported the entire blog and case-studies sections off the old site and onto the new stack, with Strapi behind both.
Here's the actual timeline, straight from the commit log — timestamps and all:

From empty route to live, SEO-clean, Strapi-backed blog and case-studies sections: about eight and a half hours of one working day. Eight commits. One developer. Each commit small enough to review in a couple of minutes.
A few things we want to be honest about, because this is the part of the post that's easiest to over-sell:
The Strapi schemas weren't designed that morning. The content model — collections, components, relations — was decided ahead of time by the team that knew the content best. Claude Code wired the frontend to a schema that already existed.
The content itself didn't have to be migrated at all. Strapi was already the headless CMS behind the old site, so every post and case study already lived there, edited and polished. We just pointed the new frontend at the same Strapi instance. There was no content move, no copy- paste, no re-editing — the only thing that changed was how that existing content gets rendered in the new design.
Polish kept landing over the following week — a responsive image ladder for Strapi assets, the filter chip set tightened to a fixed five, image sizing tuned to stop pulling full-resolution originals onto blog tiles. The migration was a day. The finish took a week of small commits.
But the part that used to be "this is a sprint" was a day. And it was a day we spent reviewing more than typing.
The comparison point that anchors the whole post: the previous bitnoise.pl build came in at 420 dev hours total across three developers — Nowak (249h), Daria (66h), Gąsiorek (105h), dev-only, no design hours included. Even allocating the proportional slice of those 420 hours that was originally blog + case studies, the rebuild of those two sections fit inside a single working day. That isn't a model trick. That's what happens when you stop typing and start steering.
The old bitnoise.pl had drifted. Not in any single embarrassing way — drift is rarely loud. The positioning had moved, the case-study mix had changed, the services we actually sold in 2026 weren't the services the homepage led with. The site was a 2023 snapshot of a 2026 company.
Fixing that is a founder-level job. Before we wrote a prompt, we wrote:
A positioning doc: who we are now, who we sell to, what proof we want on the front page.
A sitemap with intent for every route — what each page is for, not what it is.
A page-by-page content brief, pinned to that intent.
None of that came out of Claude Code. It came out of a room. The model later read every one of those documents as context, and it referred back to them often, but it didn't write any of them, and we wouldn't have wanted it to. This is the layer where LLMs are dangerously fluent — they will happily produce a plausible-sounding positioning that is, on inspection, a description of a different company.
The takeaway for anyone replicating this: don't start with the model. Start with the document the model needs to read.
Every hero headline, every services blurb, every case-study lede was written or heavily rewritten by the CEO/CTO. The model was a thesaurus and a length trimmer. We did not let it freestyle copy.
Why not? Three reasons, in order of severity:
01.
Voice drift. The model's defaults are everyone else's defaults. Letting it write the homepage is the fastest way to look like every other agency.
02.
Hallucinated capability claims. A model writing services copy is one bad prompt away from promising a capability we don't sell, on a page Google indexes.
03.
Generic SaaS-speak. Even when nothing is technically wrong, the result reads like a thousand other sites. The site is a sales asset. The words have to be ours.
The clearest place to see this is the services section on the homepage — the sticky stack of four slides (Team Augmentation, Project Delivery, AI Solutions, Custom Solutions) with the rectangle- morph transitions between them. Each slide had a model-drafted copy block and a shipped copy block, and the diff between them is what the work of voice ownership actually looks like.
For one slide (we'd pick Project Delivery — the bubble-to-progress-bar one), the pattern was the same every time:
The model's draft hedged: "We can help you deliver projects on time and on budget."
The shipped version named a concrete deliverable, anchored to an actual engagement model, and dropped every "we can" and "we help".
About 40% of the words survived. About 100% of the structure was rewritten.
That ratio held across every page of the site. The model is not the writer. The model is the writer's first-draft generator — which is useful, but it is not the same thing.
The visual language of the new site — the scroll-driven hero, the sticky services stack with the morphing rectangle, the scramble-text reveal on the highlights, the cursor-repulsion dots field, the snake animation on the Custom Solutions section, the Z-shape spacer — came entirely from the UX/UI team, as Figma flows and motion prototypes. Claude Code implemented them. It did not invent them.
This is the single biggest reason the site doesn't look AI-generic.
The unlock is Figma MCP — the Figma plug-in for the Model Context Protocol. With it connected, Claude Code can read the actual Figma file: components, frames, auto-layout, variables, design tokens, exact spacing. The implementation pass becomes translation, not invention. There is no "make it feel premium" prompt; there is "implement this frame, using these tokens, matching this motion reference."
If you're replicating this setup, the three things that earned their keep:
Wire Figma MCP on day one. A screenshot is a bad prompt. The actual frame is a good one.
Make the design tokens authoritative.
Our Tailwind scale and our Figma variables share the same numbers. The model never has to guess what gap-6 is supposed to be.
Treat motion as a loop between designer and developer, not a hand-off. This is the part the "AI writes the code" story always skips, so it's worth spelling out exactly how a single animation got built.
For every non-trivial interaction on the site, the work moved through the same loop. None of these steps is the model working alone:
01.
The designers set the two ends in Figma — the starting frame and the final frame, as real states with real values.
02.
The designers built a motion prototype showing how one becomes the other: the timing, the easing, the feel.
03.
That got turned into a written brief — a full description of the animation with its technical requirements and an implementation plan — which the developer reviewed before a line of code was written.
04.
Claude Code implemented it against the two frames, the prototype, and the brief.
05.
The developer checked the result in a real browser and on a real phone — because a curve that feels right in a prototype can feel wrong at 60fps on a mid-range Android.
06.
The developer tuned it — sometimes by going back to Claude Code, more often by hand-adjusting the raw numbers: speed, duration, easing, acceleration, delay — until the motion matched the prototype.
07.
The designers reviewed the final, running effect and signed off. Their approval, on the real thing in the browser, was the gate. Not the model's, not the developer's.
The model wrote the keyframes. It did not decide what "right" felt like, and it was never the one who got to call an animation done. That stayed a conversation between the people who designed the motion and the person who could feel it running on a real device.
Some of the distinctive interactions on the site, each one built through that loop:
The scroll-driven hero headline (landed on day one).
The sequential border-draw on the key-highlights tiles.
The services sticky stack.
The scroll-driven rectangle morph for the services visual.
The Project Delivery bubble slide.
The AI Solutions progress → spinner → tablet morph.
The shared cursor-repulsion dots canvas across the services heroes.
Each of those is a small, self-contained change you could review in a couple of minutes. None of them are tricks. They are translations.
The shape of the dev's day is different now. Less typing. More
Holding the architecture in working memory. TanStack Start + Vite 7 + React 19 + Motion 12 + Tailwind v4 + Strapi + Resend. The model can write any individual file in this stack; only the dev knows how the files fit together.
Writing precise prompts that reference existing code.
"Add this section, using the same Filters component as /blog , snapped to the Tailwind scale, motion timing matching the Project Delivery slide." The good prompts are dense with references.
Pointing the model at the right Figma frame via Figma MCP, rather than describing the design in prose.
Catching the model when it reaches for arbitrary pixel values, duplicates a state hook, or invents an API that doesn't exist. It still does all three. Less than a year ago. Still does.
Deciding when to refactor and when to ship. That call is not delegable.
The numbers behind the new shape: 53 sessions, 181 commits, ~78 focused hours. Average commit ~26 minutes of attention. Most commits land scoped tightly enough to read the diff in under a minute — and that is the new craft. The skill is no longer "write the function." The skill is "carve the work so the diff is reviewable."
CLAUDE.md that earn their keepThe repo has a small CLAUDE.md file at the root. It's about fifteen lines. It does a disproportionate amount of work because it codifies, once, the rules we'd otherwise repeat into every prompt:
01.
Always snap to the closest Tailwind scale token.
No p-[15px] . Use p-4 . The model defaults to arbitrary values when left alone; this rule kills that habit in one paragraph.
02.
Prefer responsive token chains over fixed widths
(w-16 md:w-32 lg:w-48 ).
03.
Only fall back to arbitrary values when no token is within ~1–2px of the design intent.
04.
Apply the rule to all components, refactors, and new code. No exceptions, no "this one is special."
That's it. Four rules. They remove what would otherwise be hundreds of follow-up corrections across the project. Write your own. Keep it short. Codify the things you'd otherwise have to nudge twice.
We ran every meaningful diff through two review passes:
Pass 1: a fresh Claude Code session reviews the diff
against the brief, the repo conventions, the CLAUDE.md rules, and an accessibility / SEO / performance checklist. Fresh context matters: a model reviewing its own work inside the same conversation is too forgiving. New session, no memory of the implementation, just the diff and the standards. It catches a different class of issue than the dev does, and it catches them faster.
Pass 2: the dev reads every line. Every line. Non-negotiable. The moment a team stops reading the diff is the moment subtle bugs, security issues, and quietly broken UX patterns ship. We don't have a metric for this. We have a rule.
You can see the review loop visibly working in the history:
A "fix code quality issues from review" commit landed on day 3, before the codebase even had a homepage.
An "apply code-review fixes to case studies page" commit landed twenty minutes after the case- studies scaffold itself, on the May 20 migration day.
Both of those are diffs the implementation pass produced and the review pass corrected. That is the loop doing its job.
The honest note worth landing here: code review takes longer per line than generation. The ratio inverted. Typing got roughly 10× cheaper; reading the diff is now the bottleneck. If you're staffing a project on this stack, that is the role you under-staffed in your last estimate. Fix it.
QA on this project was owned by the UX/UI team and the CTO, and it looked like this:
Every interaction tested on real devices.
Motion timing checked frame-by-frame against the prototype.
Content checked against the page-by-page brief.
Edge cases poked deliberately — empty states, slow networks, narrow viewports, Edge specifically (always Edge), reduced-motion preferences.
A short list of bugs that only humans caught — because this is the part of the post that argues against itself if we hand-wave it:
The unstyled-paint flash on first load. The stylesheet was imported the way the model thought was idiomatic; the browser briefly painted before it applied. Fixed by changing how the stylesheet loads.
The Inklusion logo broke in Edge specifically. Worked everywhere else.
The Team Augmentation hero bars were too wide on mobile — fine in the prototype, off on a real phone.
Blog tiles were pulling the full-resolution original image on small screens. The model wrote correct-looking code; only a real-device check exposed the wasted download.
None of those is a bug, exactly. Each is the model shipping what it was asked to ship, instead of what we actually wanted. That distinction is what QA is for.
The general pattern: an LLM ships what you asked for. QA catches what you forgot to ask for. You need both.
This is the part of the rebuild that tends to slide off the end of the schedule on a typical project. On this one, it landed before launch, because the dev hours we saved on implementation we redirected here.
The full list of what shipped, so you can lift any of it for your own site:
Per-page metadata on every route — unique titles, descriptions, and canonical URLs.
Auto-generated social-share images for every route, built from one template with dynamic content at build time.
A sitemap generated from Strapi at build time. The CMS is the source of truth; the sitemap rebuilds whenever content does.
An llms.txt file, an RSS feed, a search-engine ping on publish, and a page-speed scaffold.
The first one is the GEO play.
FAQ sections with structured data on every services and industries page — the kind of markup LLM-powered search actually parses.
Long-form comparison pages targeting comparison search intent.
Self-hosted fonts and prerendered marketing pages for fast first paint.
On the GEO side — Generative Engine Optimization, i.e. being citable by LLM-powered search — the moves are the same moves: clean structured data, an authoritative llms.txt , content organized around the questions users actually ask. The surface is new. The discipline isn't.
The point worth landing: none of this is hard work; all of it is work that gets cut for time on traditional rebuilds. When the implementation hours compress, the SEO budget is the first thing that gets to stop being aspirational.
If you're a prospective client looking at this post and trying to figure out what changes for your project, this is the section that answers it.
Here's our rough split of total project time — not just dev time, but the whole rebuild from positioning doc to launch:
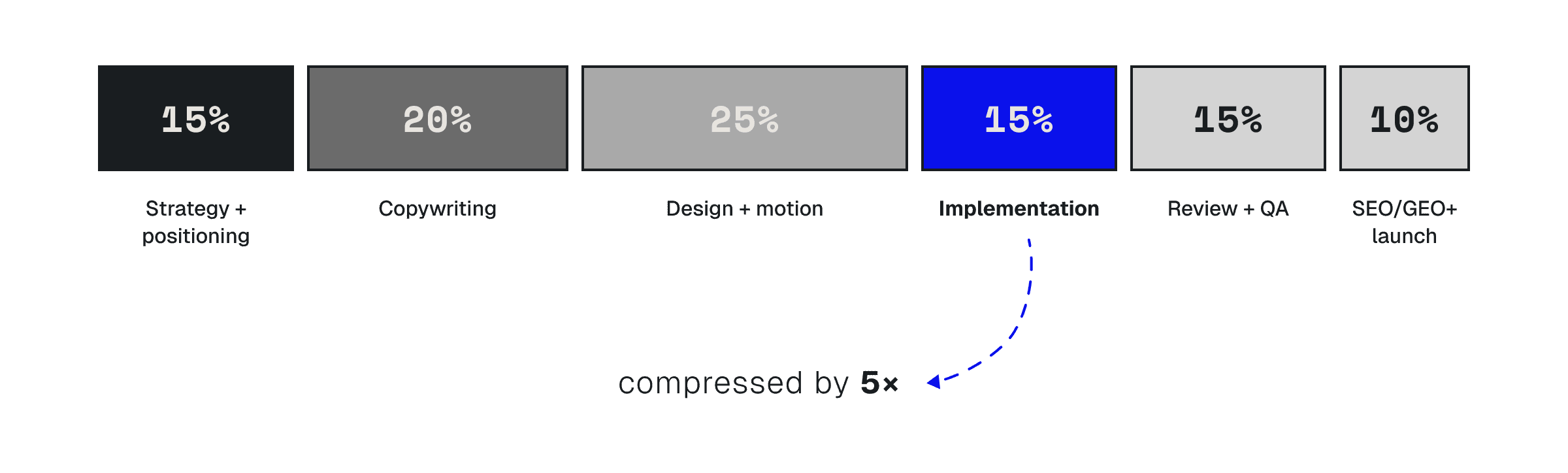
Two things to notice:
01.
The part that LLMs accelerated was already the smallest slice. Implementation is 15% of the project. We compressed a 15% slice by ~5×. The other 85% got exactly the time it always needed.
02.
The 5.4× dev-hour saving does not translate to 5.4× total project saving. It translates to the same project happening in calendar weeks instead of calendar months , with the freed-up dev hours redirected into more iterations of the parts that actually matter — voice, motion polish, SEO, edge-case QA.
That second point is the one we want prospective clients to take away. The story isn't "the model wrote the site so the budget is 5× smaller." The story is "the model compressed the bottleneck so the calendar got tighter and the other phases got more iterations."
The takeaways, in the form of bullets you can screenshot:
Treat Claude Code as the fastest junior on your team, not as the team.
Invest disproportionately in what the model can't do: positioning, voice, motion design, judgment.
Wire up Figma MCP on day one. A screenshot is a bad prompt; the actual frame, with its tokens and variables, is a good one.
Write a small, sharp CLAUDE.md .
Ours is ~15 lines. It removes hundreds of nudges.
Read every diff. The bottleneck moved from typing to reviewing. Staff for that.
Prototype animations before you implement them. "Make it feel premium" is not a prompt.
Keep humans on copy. The model's defaults are everyone else's defaults.
Run a fresh-context review pass. Same agent, new session, just the diff and the standards.
Measure in shipped pages and shipped quality, not in tokens.
Claude Code didn't replace our team. It replaced the keyboard.
The 420 hours of typing on the old site became 78 hours of judgment on the new one. The judgment is the part you can't outsource — and the part we'd never want to.
If you're a team weighing a similar redesign, or a legacy CMS migration that's been sitting on the roadmap because the dev hours never quite fit, that's the offer worth making: the same process we just ran on ourselves — Claude Code for code, Figma MCP for design handoff, role-by-role human-in- the-loop — pointed at your problem instead of ours.
The keyboard is solved. Everything else is still the work.

19 minutes read
Employer Branding Specialist

Employer Branding Specialist

Project Manager
